Project overview

Domain
The Catcher in the Rye is a novel by J.D. Salinger that was first published in 1951. It is a coming-of-age story that follows the protagonist, Holden Caulfield, as he navigates his way through adolescence and adulthood in New York City. The literary analysis performed on the writer’s background, as well as, on the recurring semantic themes present in the last two chapters of the novel, led to the formation of semantic classes. These classes give a detailed focus onto the novel’s main thematics which helped shape the novel’s ontology developed on WebOwl. The chapters have been chosen as a source rich of themes underlying the language used by the author. The scope of this project is thus focused on literary interpretation and analysis.
Knowledge extraction
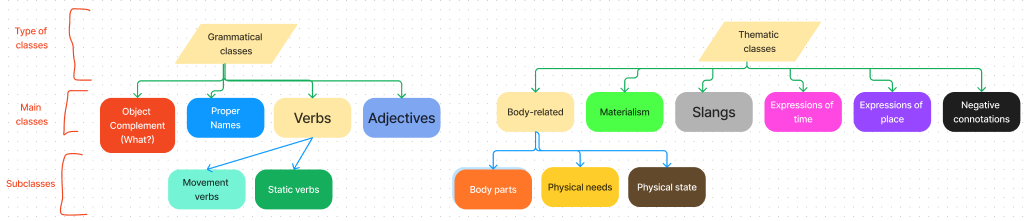
Through a deep study of the text, we decided to distinguish the tokens in grammatical and semantic classes.
As for the grammatical classes we considered the tokens which replied to the question what? as objects, those who replied to the question who? as proper names, movement verbs leading to a movement in the main character, static verbs where the situation remains still for a certain amount of time; qualitative adjectives (how?).
As for the thematic classes, which are more semantically relevant for the meaning of the novel there are body-related tokens, which are divided in body parts (ex. eyes), physical needs (ex. sleep), physical state (ex. asleep). Holden’s journey was both mental and physical, that’s why the body takes a big part of the metadata.
The materialism class was chosen because Holden’s life is spent wandering around, so this element of realism is important to understand the physical constraints of the body: one needs money to move out.
The slangs took out a big part of the text: more often present in direct conversations or in the protagonist’s thoughts, these words are important to underline the contextual roughness that Salinger adopted in taking the boy’s point of view. With the ’phoniness’ of the world, for example, the writer wants to underline the phase of life called adolescence, in which one doesn’t feel to be part of neither adulthood, nor childhood anymore.
Time expressions are a useful tool to distinguish between the real passing time and the mental perceived time by the protagonist.
Places are changed so frequently to underline the lost feeling which is the constant, also underlined by Holden’s name. Hold-en means hold on, keep on going; Caul-field: the caul is the protective covering that encloses the field of innocence. Holden tries to remain a child, but he is not anymore; he can not understand the adult world, so his only possibility is to be a Catcher in the Rye: the one who protects children from falling down the cliff of adulthood, well aware that he can not protect everyone.
The black connotation refers to negative physical and mental states.
Throughout the text we found that some tokens could have had multiple membership classes: in these ambiguous cases, the chosen class was the one most prevalent according to the meaning of the text. For example, when a word is both an object and a slang, the prevailing class is always the thematic one. In other cases where a world is both a physical state like headache, but it has a negative connotation, the negative prevails. The adopting criteria was that of always choosing the prevailing membership class.
Ontology Formation
Preliminary information:
- An ONTOLOGY is a tight relation between subject, predicate, object (triplets). The purpose of building an ontology is to create a formal representation of knowledge in a specific domain that can be used to support tasks such as information retrieval, knowledge management, and decision-making.
- QUERIES: automatic knowledge extraction.
- METADATA: declaration of the whole ontology.
- TOOLS: Google Doc, Figma, Turtle, Protégé, WebOwl, LODE.
- Ontology overview: classes, object properties, data properties. For each class: has sub-properties, has domain, has range, has sub-classes (for each class + class index).
Development:
- Classify words;
- Define what classes best fit our text;
- Which word fit in which class;
- From the general areas (semantic classes), extract more classes (logical classes), than list all words.
- Turtle: reference ontologies on the web, starting point of the ontology: querying to find the relationship between superclass, property and subclass. Turtle is the ontology declaration: you can see the relation between the triplets; you can see that a subject has multiple properties/relations.
- Once the relationship is established, the turtle URIs are exported in owl format.
- The turtle file in owl format is then debugged on Protégé. You can read about the ontology evaluation here.
- The debugged final version is then converted into json and uploaded on WebOWL.
- WebOWL is the tool used to extract a graphical representation from the Turtle querying.
- All entities in our ontology start from the URI and add after # the name of the subclass. If you click on any property you download the turtle in owl format where you can see the entities of every defined element. Look for word details on properties in webOWL.
- The final tool used was LODE, adopted to get a tabular representation of the graphical ontology; the process was that of inserting the URL we imported the ontology on Github: subject, IRI (general identifier of the class), has super-classes (property), expression of place (object).